
next 数组的意义
此处 next[j] = k;则有 k 前面的浅蓝色区域和 j 前面的浅蓝色区域相同;
next[j] 表示当位置 j 的字符串与主串不匹配时,下一个需要和主串比较的字串位置在 next[j] 处;有下图:

若当前位置 j 与主串某一个字符不匹配,则下一次比较的是 K 与主串的当前位置,这个 K 也就是next[j];由于两个浅蓝色区域相同,因此 K 前面的区域肯定与主串相同,不需比较;如下图:
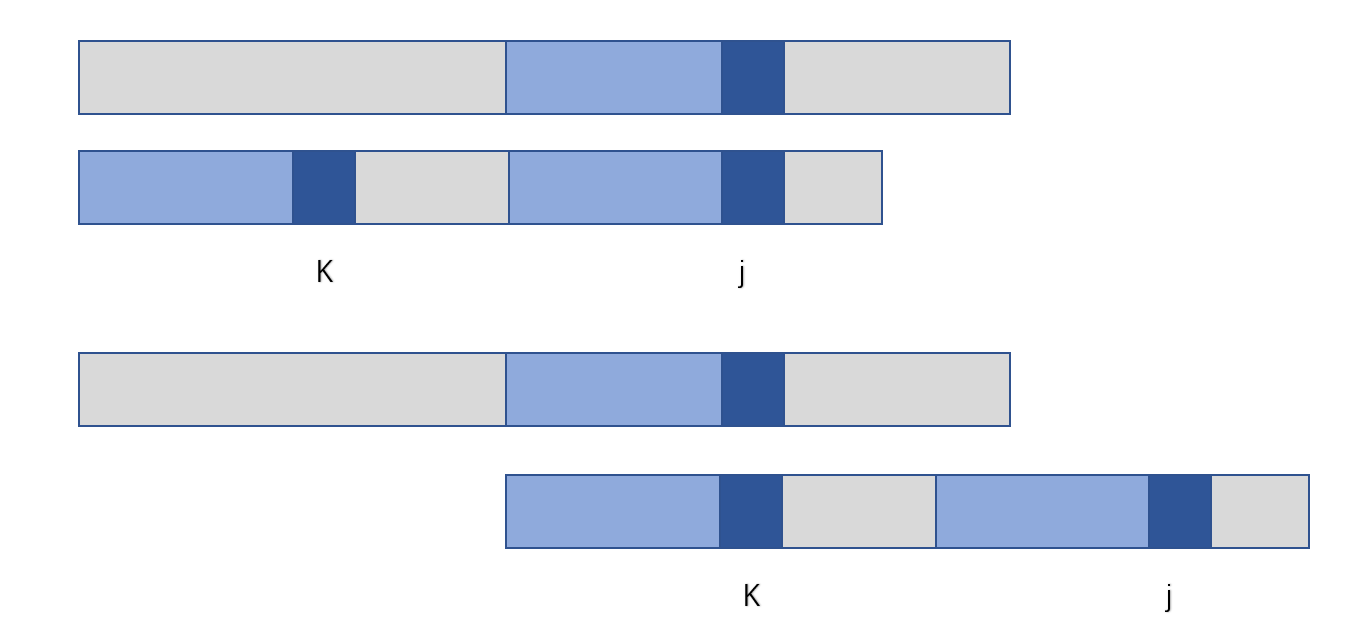
由上图可知,K 前面的区域不需比较;
next 数组的推导
从 next 数组所表达的意义可知,我们要求 next[j],首先要找到一个 K,这个 K 前面的浅蓝色区域和 j 前面的浅蓝色区域相同;如下图:
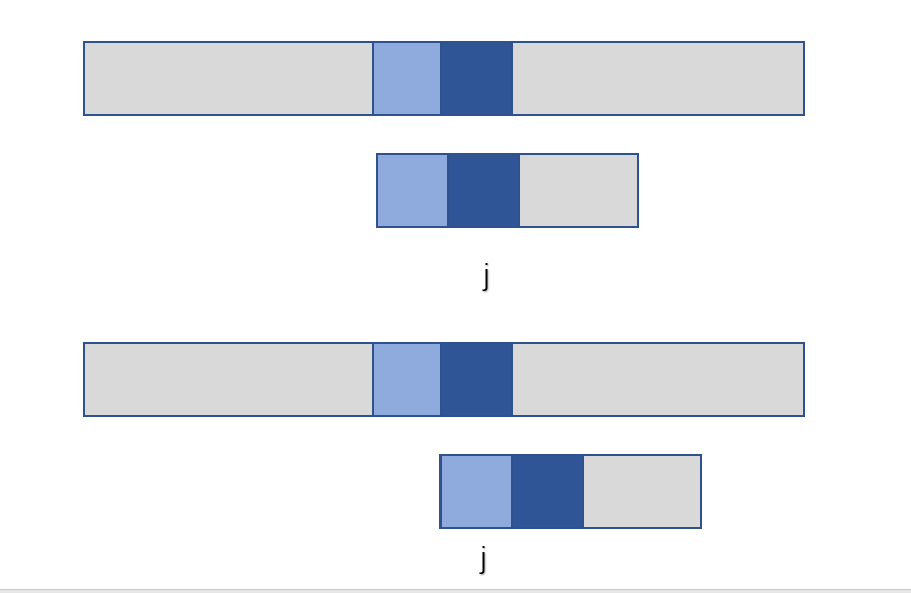
根据规定 next[1] = 0;接下来求其他的 next[j];
对于 next[2] 可得其必然为 next[2] = 1;
如下图:当第二个元素不匹配时,j 将退回到 1 处进行比较,因此 next[2] 一定为 1;
接下来是一般情况的推导,此处使用递推法进行推导,即已知 next[j] 求 next[j + 1];
若 next[j] = k 则有下图:

由于 next[j = k,可知浅蓝色部分相同;接下来分两种情况讨论;
-
ch[K] == ch[j],这种情况时,可以得到下图;

由图可知:对于 j + 1,能够找到一个 K + 1 使得有浅蓝色区域相同,那么当 j + 1 不匹配时,下一次将比较 K + 1 和主串;因此 next[j + 1] = K + 1 = next[j] + 1;
-
ch[K] != ch[j],这种情况就变的复杂,这也是整个 KMP 算法中最难理解的部分;
从本节的开头可以知道,求 next[j + 1] 最关键的一点在于求 j + 1 之前有多长的后缀和前缀匹配,即找出多大的浅蓝色区域匹配;我们现在面对的图如下:

我们的目的是找到一个 K1 使得出现下列情况:找到 K1 使得浅蓝色部分相同;

要想浅蓝色部分相同,分为两个部分,使得 1 和 2 相同,使得 K1 和 j 相同;

想要让 1 和 2 相同是难以比较的,但是可以转化为另一个问题,如下图:

想要找出 1 和 3 相同的区域,等价与找到 1 和 2 相同的区域;为什么呢?因为 next[j] = K,因此 j 前面与 K 前面相同如下图:
这个等价关系非常重要,是这部分推导的关键;将其单独抽离出来如下图:

那么如何得到 K1 使得 1 和 2 相同呢?回到文首 next[j] 所表示的意义,next[j] = k;则有 k 前面的浅蓝色区域和 j 前面的浅蓝色区域相同 而 next[K] 是在 j 前面的是已知的,因此可得 K1 = next[K],此时得到的 K1 即可满足 1 和 3 相同;
到此就解决了 1 和 3 相等的问题,直接比较 K1 和 j 若两者相同,则可得到下图;
那么 next[j + 1] = K1 + 1 = next[K] + 1 = next[next[j]] + 1;
那么若 ch[j] != ch[K1] 呢?那么就又演化为如下问题:

这个图和本小节开始的图相同,那么按照此方法解决即可;
可得结果:next[j + 1] = next[K1] + 1 = next[next[K]] + 1 = next[next[next[j]]] + 1
若下一次 K2 依然和 j 不相等,那么又接着递归即可;一直到 Kn = 0;
一个例子
接下来使用上面的结论来计算一个字符串的 next 数组;
有数组 ababaaababaa 转化为如下表:
| S | a | b | a | b | a | a | a | b | a | b | a | a |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| next | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 2 | 3 | 4 | 5 | 6 |
按如下顺序填表的 next 栏:
- 对于 next[1] 规定为 0,根据前面的分析:next[2] = 1;
- 对于 next[3],则观察 2 和 next[2] = 1,即 b 和 a,不相等;而next[next[2]] = 0,因此 next[3] = 1;
- 对于 next[4],观察 3 和 next[3] = 1,即 a 和 a,相等,故 next[4] = next[3] + 1 = 2;
- 对于 next[5],观察 4 和 next[4] = 2,即 b 和 b,相等,故 next[5] = next[4] + 1 = 3;
- 对于 next[6],观察 5 和 next[5] = 3,即 a 和 a,相等,故 next[6] = next[5] + 1 = 4;
- 对于 next[7],观察 6 和 next[6] = 4,即 a 和 b,不相等,next[next[6]] = 2,与 6 比较即 b 和 a,不相等,继续递归 next[next[next[6]]] = next[next[4]] = next[2] = 1;比较 1 和 6 即 a 和 a,相等,因此 next[6] = next[next[next[6]] + 1 = 2;
- 对于 next[8],观察 7 和 next[7] = 2,即 a 和 b,不相等,next[next[7]] = 1,1 和 7相等,因此 next[8] = next[next[7]] + 1 = next[2] + 1 = 2;
- 对于 next[9],观察 8 和 next[8] = 2,即 b 和 b,相等,故 next[9] = next[8] + 1 = 3;
- 对于 next[10],观察 9 和 next[9] = 1,即 a 和 a,相等,故 next[10] = next[9] + 1 = 4;
- 对于 next[11],观察 10 和 next[10] = 2,即 b 和 b,相等,故 next[11] = next[10] + 1 = 5;
- 对于 next[12],观察 11 和 next[11] = 3,即 a 和 a,相等,故 next[12] = next[11] + 1 = 6;
代码实现
通过以上分析得到的获取 next 数组的代码如下:
void get_next(String T, int next[]) { int k = 0, j = 1; next[1] = 0; while (j < T.length) { if(k == 0 || T.ch[k] == T.ch[j]) { k++; j++; next[j] = k; } else { k = next[k]; } } }那么接下来的 KMP 算法代码就比较容易了:
int KMP(String S, String T, int next[]) { int i = 1, j = 1; while (i <= S.length && j <= T.length) { if(j == 0 || S.ch[i] == T.ch[j]) { i++; j++; } else { j = next[j]; } } if(j > T.length) { return i - T.length; } else { return 0; } }测试代码如下:
#include<iostream> using namespace std; const int MAX = 255; typedef struct { char ch[MAX]; int length; } String; void InitiString(String &s, char chars[]) { int len = 0; while(chars[len] != '\0') { s.ch[len + 1] = chars[len]; len++; } s.length = len; } void get_next(String T, int next[]) { int k = 0, j = 1; next[1] = 0; while (j < T.length) { if(k == 0 || T.ch[k] == T.ch[j]) { k++; j++; next[j] = k; } else { k = next[k]; } } } int KMP(String S, String T, int next[]) { int i = 1, j = 1; while (i <= S.length && j <= T.length) { if(j == 0 || S.ch[i] == T.ch[j]) { i++; j++; } else { j = next[j]; } } if(j > T.length) { return i - T.length; } else { return 0; } } int main() { char char1[20] = "aabaabaabaac"; char char2[20] = "aabaac"; String S, T; InitiString(S, char1); InitiString(T, char2); int next[MAX]; get_next(T, next); int index = KMP(S, T, next); printf("%d", index); return 0; }输出结果:
7热门文章
- 1月15日 | Winxray Github每天更新20.4M/S免费节点订阅地址分享
- 12月26日 | Winxray Github每天更新22.8M/S免费节点订阅地址分享
- 动物疫苗接种方法有哪些种类的 动物疫苗接种方法有哪些种类的图片
- HTML URL 编码转换表
- 12月8日 | Winxray Github每天更新22.3M/S免费节点订阅链接
- 动物疫苗接种方法及注意事项有哪些呢 动物疫苗接种方法及注意事项有哪些呢视频
- 11月22日 | Winxray Github每天更新19.4M/S免费节点订阅链接
- HashMap中红黑树插入节点的调整过程分析_在线工具
- 给动物打的狂犬疫苗有效期多久啊(给动物打狂犬疫苗打几针)
- vue+Echarts绘制动态折线图